1. 너비우선탐색
- 큐를 이용하여 깊이가 같은 노드를 모두 방문하고 깊이를 증가시키며 탐색하는 알고리즘이다.
2. 동작원리
1) 지정한 시작 노드에서부터 시작
2) 자식 노드들을 큐에 저장한다
3) 큐에 저장된 노드를 차례로 방문하면서 방문한 노드의 자식들을 큐에 저장
4) 큐에 있는 요소를 방문하면서 2) 3)의 과정을 반복
5) 모든 노드를 방문하면 탐색을 종료
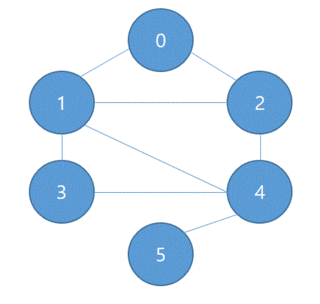
3. 소스
- #include<stdio.h>
- int front = -1;
- int rear;
- void inqueue(int *,int); // 큐에 데이터를 삽입하는 연산
- int dequeue(int *); // 큐에서 데이터를 빼는 연산
- int queueempty(); // 큐가 비어있는지 검사
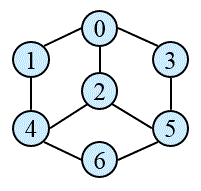
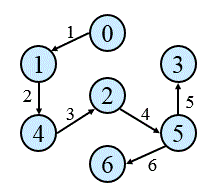
- int matrix[6][6] = {{0,1,1,0,0,0},
- {1,0,1,1,0,0},
- {1,1,0,1,1,0},
- {0,1,1,0,1,1},
- {0,0,1,1,0,0},
- {0,0,0,1,0,0}};
- int visit[6];
- int main(void)
- {
- int a=0;
- int b=0;
- int now = 0;
- int queue[40] = {0,};
- visit[0] = 1; // 처음방문할 정점
- inqueue(queue,0);
- while(queueempty())
- {
- now = dequeue(queue); // 큐의 원소를 빼내 인접 노드를 찾는다
- if(visit[now] == 0) // 인접노드중 방문하지 않은 노드를 찾기위해 vist배열을 검사
- {
- visit[now] = 1;
- }
- for(a=0;a<6;a++) // 현재 노드의 인접 노드를 큐에 저장하기 위한 for문
- {
- if(matrix[now][a] == 1 && visit[a] == 0)
- inqueue(queue,a);
- }
- }
- return 0;
- }
- int queueempty()
- {
- if(front == rear)
- return 0;
- else
- return 1;
- }
- void inqueue(int *queue, int data)
- {
- if(rear == 40)
- else
- (*(queue + (rear++))) = data;
- }
- int dequeue(int * queue)
- {
- int data;
- data = (*(queue+(++front)));
- return data;
- }
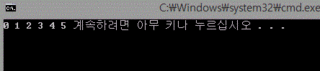
4. 결과
'c언어(알고리즘)' 카테고리의 다른 글
| 큐(Queues) - 배열로 구현(The implementation with the array) (0) | 2016.11.02 |
|---|---|
| 깊이우선탐색(DFS : Depth First Search) (0) | 2016.11.01 |
| 스택(Stacks) - 연결리스트로 구현(The implementation with the linked lists) (0) | 2016.11.01 |
| 스택(Stacks) - 배열로 구현(The implementation with the array) (0) | 2016.11.01 |
| 힙 정렬 (Heap-Sort) (0) | 2016.11.01 |